
源代码:
https://github.com/CrazyAndy/rag-all-techniques/blob/main/app/02_semantic_chunking.py
一、拆分chunks
段落1 这是一个神话故事,传说在很久很久以前,天下分为东胜神洲、西牛贺洲、南赡部洲、北俱芦洲。在东胜神洲傲来国,有一座花果山,山上有一块仙石,一天仙石崩裂,从石头中滚出一个卵,这个卵一见风就变成一个石猴,猴眼射出一道道金光,向四方朝拜。
段落2 那猴能走、能跑,渴了就喝些山涧中的泉水,饿了就吃些山上的果子。整天和山中的动物一起玩乐,过得十分快活。一天,天气特别热,猴子们为了躲避炎热的天气,跑到山涧里洗澡。它们看见这泉水哗哗地流,就顺着涧往前走,去寻找它的源头。
段落3 孙悟空见没办法留下来,就拜别了菩提祖师,又和各位师兄告别,然后念了口诀,驾着筋斗云,不到一个时辰,就回到了花果山水帘洞,看到花果山上一片荒凉破败的景象,很是凄惨。
Simple RAG 按照每1000个字符拆分,可能会拆散语义相似的块
Semantic Chunking 让语义相似的块在一起
二、关键点
使用算法 分析 相邻 两段 文字 向量相似性 相对较低的地方,作为切分点
1. 计算每句话和相邻语句的相似度
similarities = []
for i in range(len(knowledge_embeddings) - 1):
similarity_score = cosine_similarity(knowledge_embeddings[i], knowledge_embeddings[i + 1])
similarities.append(similarity_score)
2. 计算切分点
threshold_value = np.percentile(similarities, threshold)
return [i for i, sim in enumerate(similarities) if sim < threshold_value]
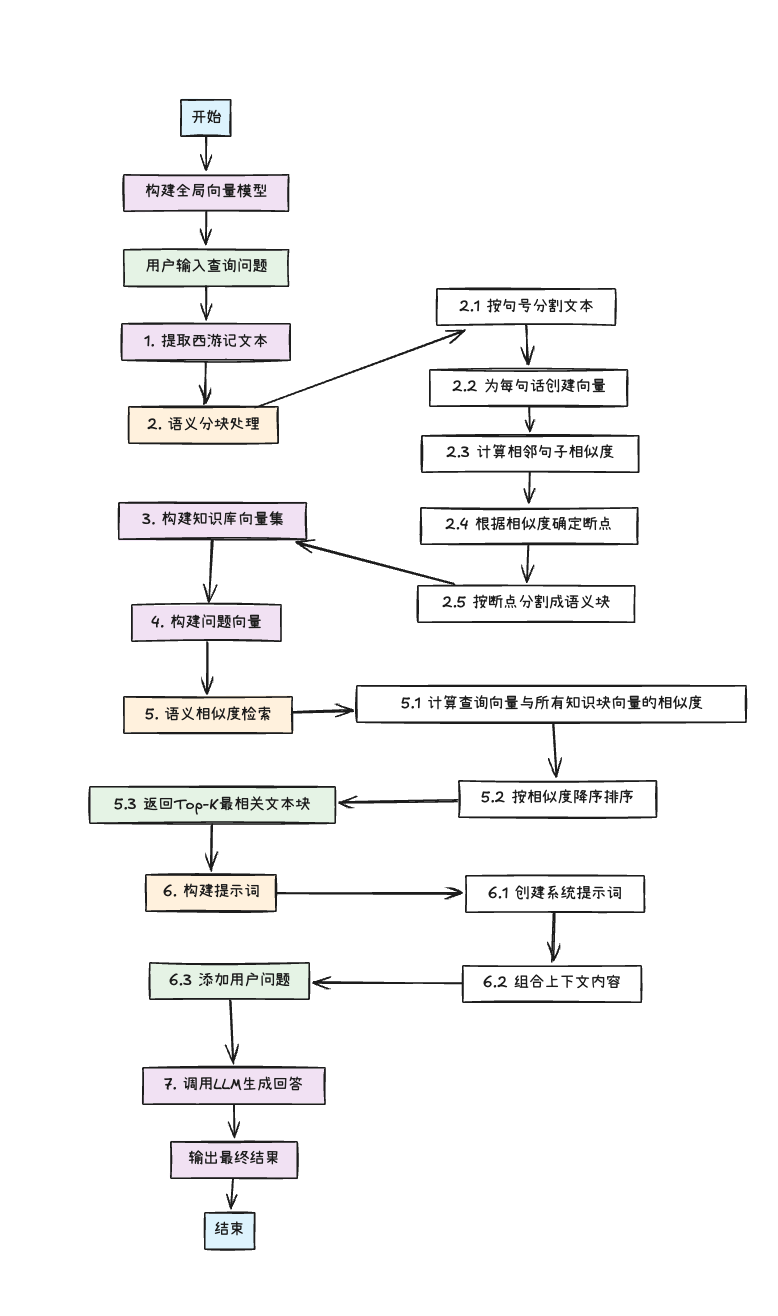
三、流程图

{kind=link}
大家一起来讨论