
我们尝试改进数据(使用分块策略)和查询(使用转换)。现在,让我们关注检索过程本身 。简单的相似性搜索通常会返回相关和不相关的结果。
源代码
https://github.com/CrazyAndy/rag-all-techniques/blob/main/app/07_rerank.py
一、相似性≠相关性
(一). 相似性
主要关注的是文本片段在词汇、语法和结构上的相似程度。它更多地侧重于文本的表面形式。
1. 词汇相似性
指两个文本片段中词汇的重叠程度。
- 句子1:我喜欢吃苹果。
- 句子2:我喜欢吃香蕉。
- 这两个句子在词汇上有很高的相似性,因为它们有三个相同的词(“我”、“喜欢”、“吃”)
2. 语法相似性
指两个文本片段在语法结构上的相似程度。
- 句子1:我喜欢吃苹果。
- 句子2:我喜欢吃水果。
- 这两个句子在语法结构上是相似的,都是主谓宾结构
3.结构相似性
指两个文本片段在句子结构或篇章结构上的相似程度。
- 文本1:我去了商店,买了苹果。
- 文本2:我去了超市,买了香蕉。
- 这两个文本在结构上是相似的,都是两个句子组成的简单篇章,且句子结构相似。
(二)相关性
主要关注的是文本片段在意义上的相关程度。它更多地侧重于文本的内在含义和逻辑关系。
1. 主题相关性
- 定义:主题相关性是指两个文本片段是否涉及相同或相关的主题。
- 例子:
- 文本1:苹果是一种水果,含有丰富的维生素C。
- 文本2:香蕉也是一种水果,含有丰富的钾。
- 这两个文本在主题上是相关的,因为它们都讨论了水果及其营养成分。
2. 上下文相关性
- 定义:上下文相关性是指两个文本片段在上下文环境中的相关程度。
- 例子:
- 文本1:在水果店,我看到了很多新鲜的苹果。
- 文本2:我决定买一些苹果回家。
- 这两个文本在上下文上是相关的,因为它们都涉及在水果店的情境中。
3. 逻辑相关性
- 定义:逻辑相关性是指两个文本片段在逻辑上的相关程度。
- 例子:
- 文本1:因为下雨,所以地面很湿。
- 文本2:地面很湿,所以我不小心滑倒了。
- 这两个文本在逻辑上是相关的,因为它们之间存在因果关系。
(三) 区别与联系
1. 区别
-
语言相似性:
-
侧重于表面形式:主要关注词汇、语法和结构上的相似性。
-
容易量化:可以通过词频、词嵌入等技术进行量化。
-
不考虑语义:即使两个句子在词汇和结构上相似,它们的语义可能完全不同。
-
-
语义相关性:
-
侧重于内在含义:主要关注文本片段在意义上的相关性。
-
难以量化:需要更复杂的语义分析和上下文理解。
-
考虑语义:即使两个句子在词汇和结构上不同,它们的语义可能非常相似。
-
2. 联系
-
互补性:语言相似性和语义相关性是互补的。语言相似性可以帮助模型快速识别文本的表面形式,而语义相关性则帮助模型理解文本的内在含义。
-
共同作用:在实际应用中,模型通常会同时考虑语言相似性和语义相关性,以更全面地理解和生成文本。
(四) 在大模型中的应用
大语言模型通过复杂的算法和大量的数据训练,能够理解和生成具有相似性和相关性的文本。具体来说:
-
语言相似性:
-
词嵌入(Word Embeddings):将单词映射到高维向量空间,相似的单词在向量空间中距离较近。
-
上下文嵌入(Context Embeddings):如BERT等模型,能够捕捉上下文中的词汇相似性。
-
-
语义相关性:
-
上下文建模(Context Modeling):通过上下文信息理解文本的语义。
-
逻辑推理(Logical Reasoning):通过逻辑关系理解文本的内在含义。
-
(五) 总结
-
语言相似性:关注词汇、语法和结构上的相似性,侧重于文本的表面形式。
-
语义相关性:关注文本在意义上的相关性,侧重于文本的内在含义。
在实际应用中,大语言模型会综合考虑语言相似性和语义相关性,以更好地理解和生成自然语言。
二、rerank思路
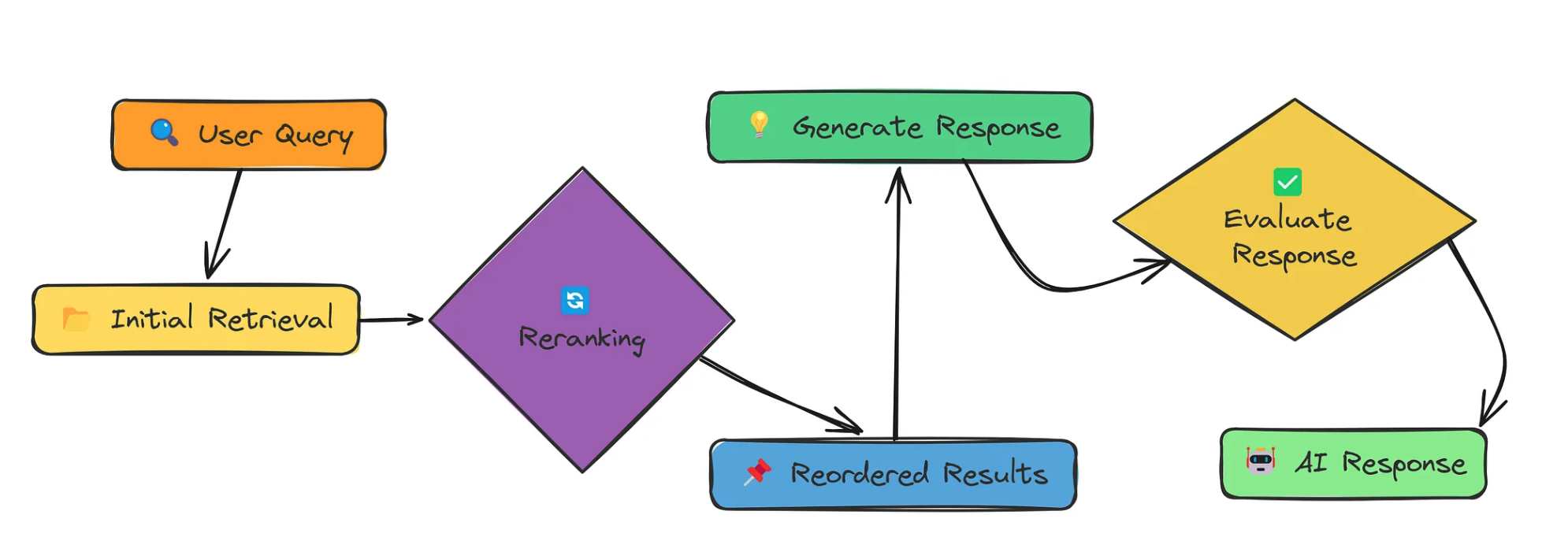
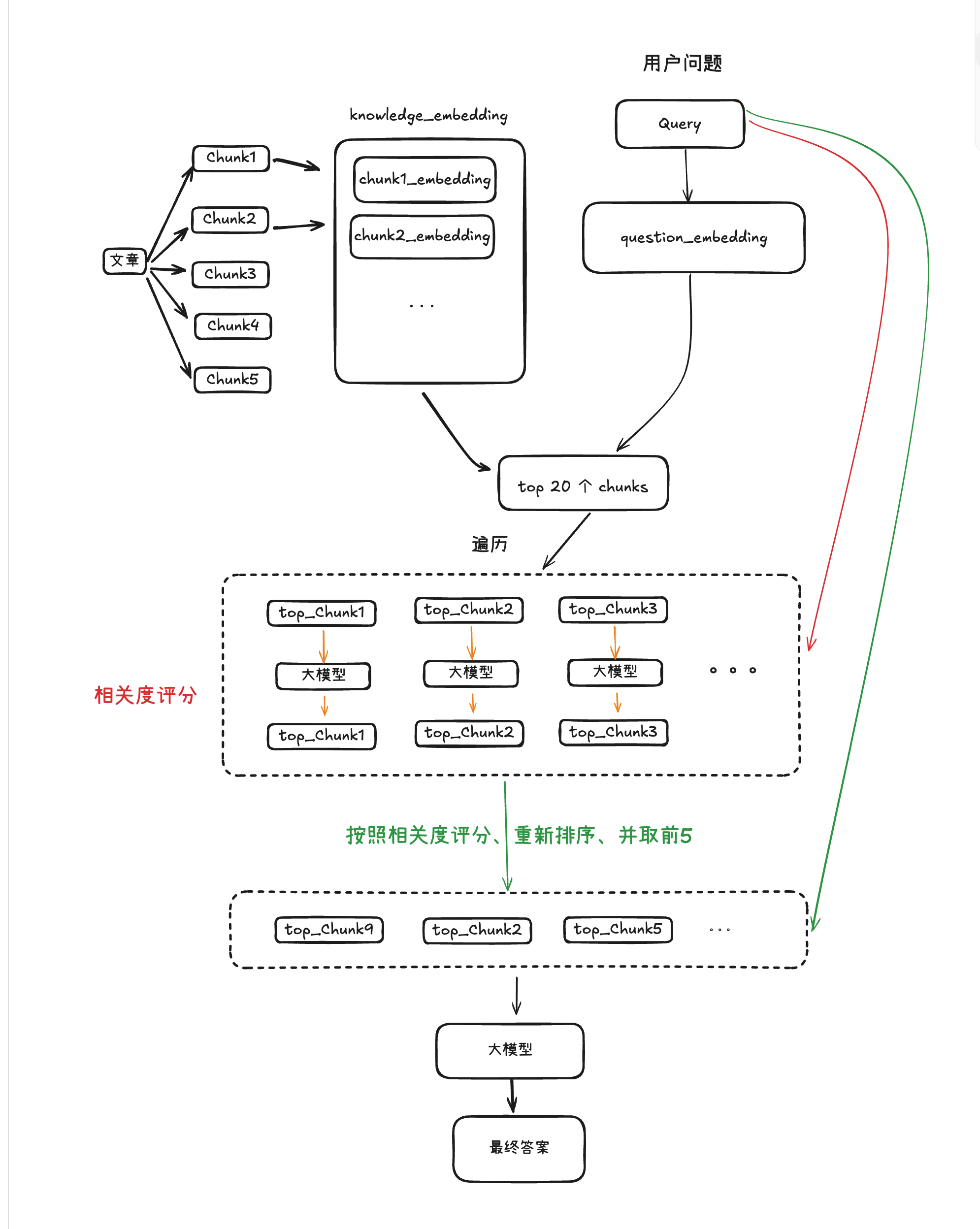
三、程序设计
{kind=link}
大家一起来讨论