
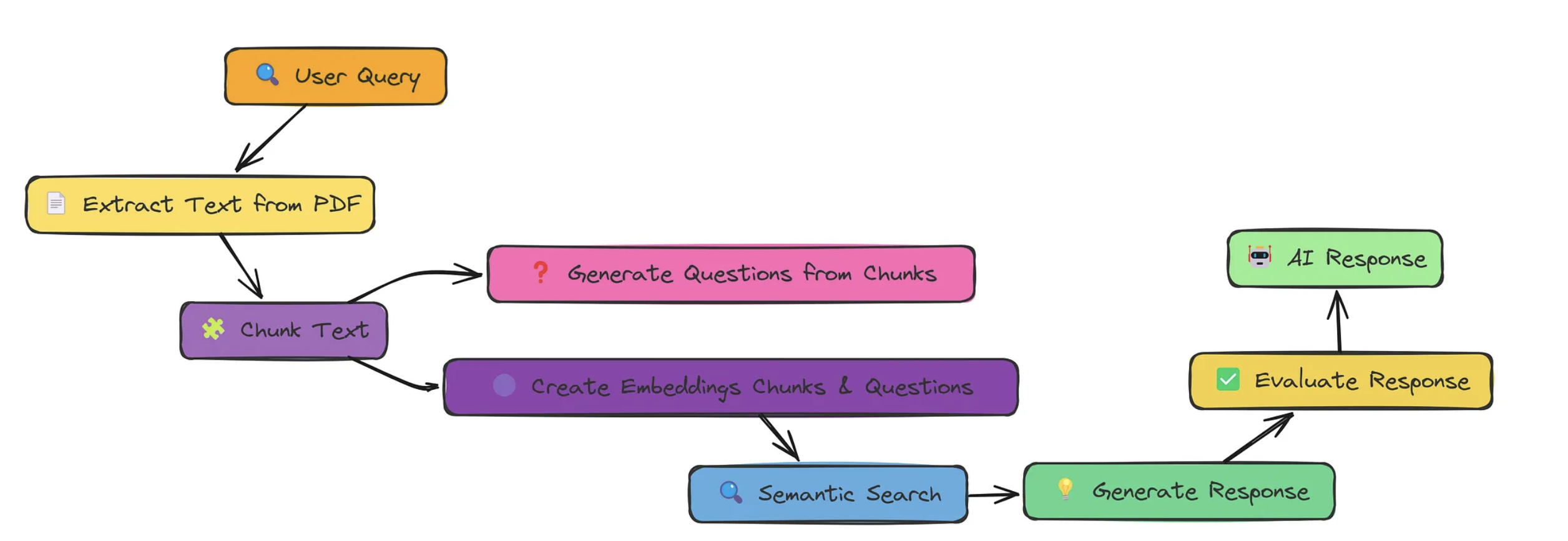
增强的 RAG 方法,通过文档增强和问题生成来改进。通过为每个文本块生成相关的问题,我们提高了检索过程,从而使得语言模型能够提供更好的响应。
源代码
https://github.com/CrazyAndy/rag-all-techniques/blob/main/app/05_doc_augmentation.py
一、架构图
二、实现思路
三、代码
https://github.com/CrazyAndy/rag-all-techniques/blob/main/app/05_doc_augmentation.py
Chunk处理与问题生成
-
提高召回率:为每个chunk生成多个问题,可以提高chunk的被召回率。
-
实现思路:
-
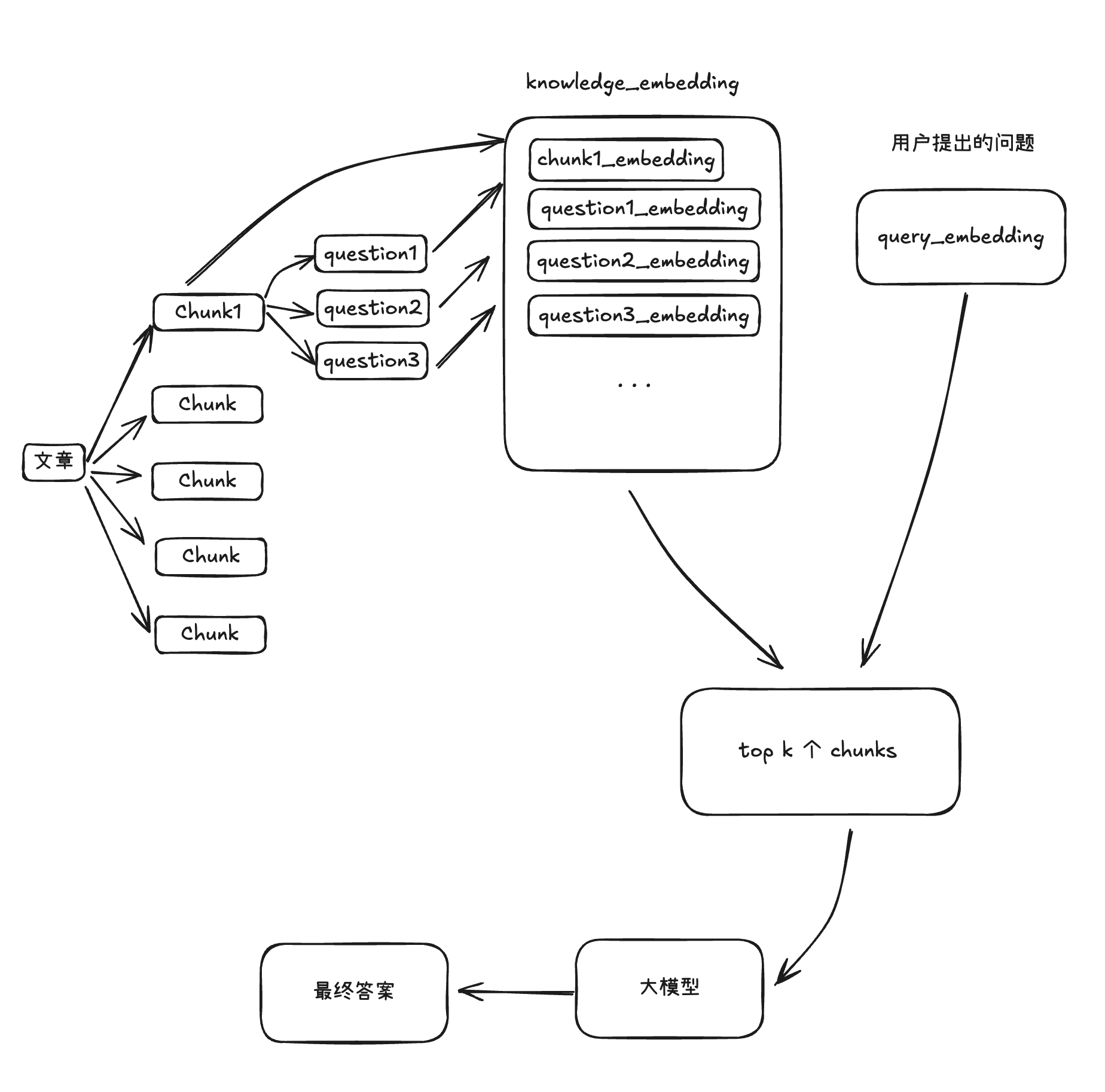
将文章定长拆分成多个chunk。
-
为每个chunk生成多个只有该chunk可以解释的问题。
-
将chunk和问题一起进行向量化处理。
-
将这些向量与用户提出的问题进行相似度计算。
-
最终得到多个chunk,每个chunk的ID不重复。
-
核心代码实现
-
知识库处理:
-
遍历知识库的chunk,为每个chunk生成多个问题。
-
将问题放入question data集合中。
-
使用系统提示词生成问题,提示词强调生成简洁、可回答的问题,聚焦核心信息和关键概念。
-
使用正则表达式从大模型输出中提取多个问题。
-
-
相似度检索:
-
遍历知识块数据集,将每个知识块与用户问题进行相似度计算。
-
遍历问题数据集,将每个问题与用户问题进行相似度计算。
-
将评分结果存入评分集,进行倒序排列。
-
最终评分集包含chunk的ID、内容和评分。
-
代码执行流程
-
执行流程:
-
提取文档内容,定长拆分chunk。
-
为每个chunk生成多个问题。
-
进行向量化处理和相似度计算。
-
打印评分和chunk的前100个字符。
-
将TOPK的chunk塞入用户提示词中,生成最终答案。
-
示例问题与答案
-
问题:铁扇公主的芭蕉扇借给孙悟空了吗?
-
答案:铁扇公主的芭蕉扇最终借给了孙悟空。
四、总结
-
核心思路:通过为chunk生成多个只有该chunk可以解释的问题,将用户问题与chunk之间建立沟通桥梁,提高对用户问题真正有意义的chunk的召回率。
-
优势:虽然看似多走了一步,但大大提高了chunk的召回率,让大模型得到更加精确的答案。

{kind=link}
大家一起来讨论