
我们一直在添加越来越多的上下文、相邻块、生成的问题和整个片段。但有时, 少即是多 。 LLM 的上下文窗口有限,在其中塞满不相关的信息可能会损害性能。
源代码
https://github.com/CrazyAndy/rag-all-techniques/blob/main/app/09_contextual_compression.py
上下文压缩是关于选择性的。我们检索了大量的上下文,但随后我们对其进行压缩,只保留与查询直接相关的部分。
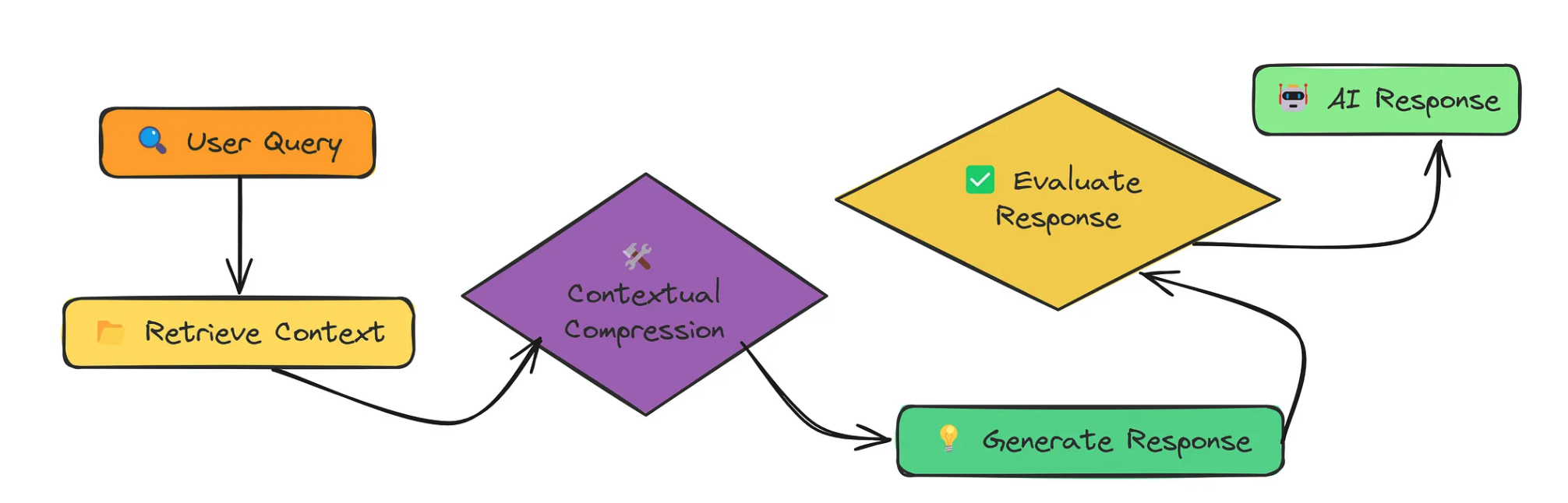
设计思路
我们一直在添加越来越多的上下文、相邻块、生成的问题和整个片段。但有时, 少即是多 。 LLM 的上下文窗口有限,在其中塞满不相关的信息可能会损害性能。
https://github.com/CrazyAndy/rag-all-techniques/blob/main/app/09_contextual_compression.py
上下文压缩是关于选择性的。我们检索了大量的上下文,但随后我们对其进行压缩,只保留与查询直接相关的部分。
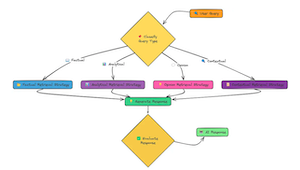
>我们探索了改进 RAG 的各种方法:更好的分块、添加上下文、转换查询、重新排名,甚至纳入反馈。但是,如果最好的技术取决于所问问题的类型呢?这就是自适应 RAG 背后的想法。 # 源代码 https://github.com/CrazyAndy/rag-all-techniques/blob/main/app/11_adaptive.py 我们在这里使用四种不同的策略: 1. **Factual Strategy:** Focuses on retrieving precise ...

{kind=link}
大家一起来讨论