
我们发现语义分析拆分chunk,虽然看起来是一个很好的拆分原则,但是它有一个致命缺陷在于,它定义的块过于专注,它们可能遗漏了周围文本中至关重要的上下文。所以说,事实上并没有提高我们的结果。
源代码:
https://github.com/CrazyAndy/rag-all-techniques/blob/main/app/03_context_enriched.py
场景介绍
第3回 齐天大圣大闹天宫_西游记白话文小说
孙悟空不但没有被熔化,反而炼就了一双火眼金睛。他从耳朵中掏出金箍棒,迎风一晃,变成碗口那么粗。==悟空抡起如意棒,一路指东打西,直打到灵霄殿上==,大声叫喊着∶“皇帝轮流做,玉帝老头,你快搬出去,把天宫让给我,要不,就给你点厉害看看!”幸好有三十六员雷将,二十八座星宿赶来保护,玉帝才能脱身。==玉帝立即派人去西天请如来佛祖==。如来一听,带着阿傩、伽叶两位尊者,来到灵霄殿外,命令停止打斗,叫悟空出来,看看他有什么本事。悟空怒气冲冲地看着如来,根本就不把如来放在眼里。
搜索问题: ==玉帝为什么立即派人去西天请如来佛祖?==
一、语义拆分chunk潜在问题分析
1. 语义连贯性丢失
- 问题:即使两个句子在向量空间中相似度较低,它们可能在语义上仍然紧密相关
- 例子:在《西游记》中,”悟空抡起如意棒,一路指东打西,直打到灵霄殿上”和”玉帝立即派人去西天请如来佛祖”这两句话相似度可能不高,但它们描述的是同一个事件的不同阶段,分割后可能丢失关键上下文
2. 关键信息被截断
- 问题:重要的实体、事件或概念可能跨越多个句子,强制分割会破坏完整性
- 例子:人物介绍、复杂事件描述、因果关系等可能被不恰当地分割
3. 局部最优vs全局最优
- 问题:只考虑相邻句子的相似度,忽略了更远距离的语义关联
- 例子:一个段落可能整体讨论同一个主题,但中间有几句过渡性内容,按相邻相似度分割会破坏整体语义
4. 上下文窗口过小
- 问题:只考虑相邻句子,可能错过重要的长距离依赖关系
- 例子:代词指代、话题延续、情节发展等可能需要更宽的上下文窗口
二、上下文丰富感知检索
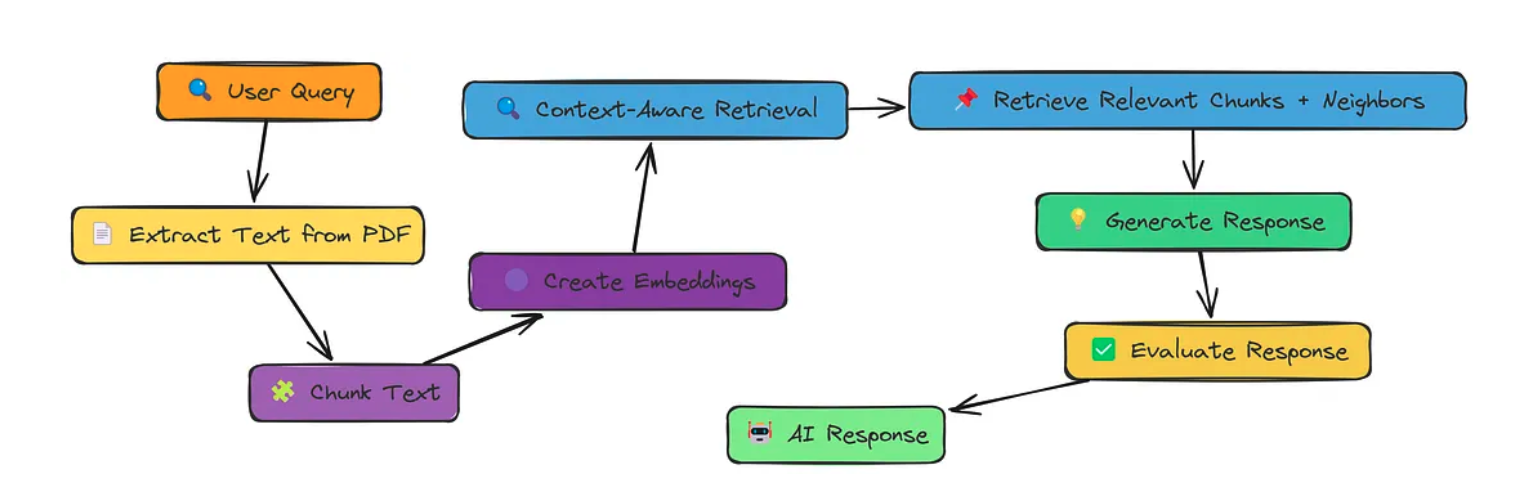
核心点: 检索相关块及其邻居以获得更好的完整性
三、关键代码
# 获取最相关块的索引
top_index = similarity_scores[0][0]
# 定义上下文包含的范围
# 确保不会超出 text_chunks 的边界
start = max(0, top_index - context_size)
end = min(len(knowledge_chunks), top_index + context_size + 1)
# 返回最相关的块及其相邻的上下文块
results = []
for index in range(start, end):
results.append({
'text': knowledge_chunks[index],
'score': similarity_scores[index][1],
'index': index
})
return results

{kind=link}
大家一起来讨论